|
Memory Parity Errors: Causes and Suggestions
Parity Memory
Error Correcting Code Memory
Results of Mixing Parity and ECC
Error Correcting Code-Parity (ECC-P) Memory
Requirements for Using ECC-P
Enabling ECC-P
Performance, ECC vs. ECC-P vs. EOS
ECC on SIMMs (EOS) Memory
Mixing EOS and Parity?
Memory Parity Errors: Causes and Suggestions
Preface- This is written for the clone systems. Some stuff is not exactly
true for Micro Channel systems. However, you will recognize some reasons
for Traps under OS/2 and the odd memory errors that seem incomprehensible.
From MS, KB Article Q101272
Both IBM OS/2 2.x and Window NT seem to experience problems
which appear to be associated with system memory in some circumstances.
It can be frustrating to have a system that is able to run DOS, Windows
3.1 or OS/2 1.x and suddenly find it cannot run Windows NT due to this
problem. The first issue to clear up is that not all NMI errors are due
to memory. Other boards in the system can cause this problem and components
directly on the system motherboard can be at fault. When memory is at fault,
it is usually for the following reasons:
1. Memory not functioning at the specified
access rate as required by system board.
If the system specification calls for 80 ns access rate,
Windows NT most likely fails if memory is accessing at a slower rate such
as 90 ns. Even though the chips may be marked as 80 ns, in testing, some
fail to meet this access rate. Quite often memory chips run at a slower
speed when they reach operating temperature. This produces an effect called
"speed drift." The symptoms are a system which runs Windows NT when first
turned on; however, after 15 minutes or so, the system starts having memory
errors. A high quality SIMM tester can cycle the chips through various
voltage and heat cycles, so this is fairly easy to see.
2. Memory meets specs, but speeds are different
between SIMMs.
The average access rate may be 70 ns on one SIMM module
while the next is running at 60 ns. We have found SIMMs stamped at the
factory to be rated at a 70 ns average access rate to actually be running
as fast as 50 ns. Although the SIMMs are obviously well under the system
required access specification, the difference of 10 ns or more between
them can often cause problems on some systems. An interesting note here
is that you can move these to a different system board which is using a
different BIOS and chip set, and it may not have any memory problems. This
is because each BIOS and chip set regulate the "refresh wait states" used
for timing, and this difference often allows for variance in speed to be
acceptable. If your system's BIOS allows you to adjust the "wait states"
for memory refresh, this often will allow the system to run with SIMMs
or DRAM memory chips which are running at different access rates. The downside
to increasing the number of wait states is a slower system.
3. Individual chips on SIMM module run at different
access rates.
A difference of 10 ns or more between bits has been known
to cause problems. This once again can be regulated somewhat by the BIOS
and chip set of the system board if it allows you to lengthen the refresh
wait states for memory access.
4.One of the memory chips is being affected
by "cell leakage."
This is a true parity error and is also known as a "soft
error." This occurs when the change in the state of an individual cell
(a zero or one) electrically leaks into a neighboring cell changing it's
state. When the memory is read back, it no longer matches the parity bit's
checksum value and an NMI is issued to the processor signaling a parity
error has occurred. This memory SIMM must be replaced. If problems persist
with replacement chips, there is quite possibly a voltage or heat anomaly
occurring with the socket or circuitry which is damaging the chips.
5.Cache memory is another thing to suspect.
In some instances the Cache memory access rates were too
slow and caused enormous problems. On most Intel-based 486 computers, a
15 ns to 25 ns is normal. You will most likely have problems if it is slower
than 25 ns. The system manufacturer can provide the specifications and
locations of these chips.
In general, you should first carefully clean the system of dust.
This includes the areas allowing ventilation so that heat does not build
up abnormally. The contacts of all boards and SIMMs should be cleaned.
You can use the eraser of a pencil to do this, thus ensuring good contacts.
Ed. Uh, keep your
fingers off the contacts in the first place. Never saw a super grungy PS/2
SIMM yet. Dusty, hell yes...
From Dr. Jim
> I think I would try to clean the contacts on all the removable
memory with a pencil eraser, corrosion may be causing some flaky electrical
connections.
Not a good plan, if the contacts are gold plated. A pencil eraser
will strip away some of the gold. The edges of a dollar bill, or
a chunk of good quality bond typing paper, folded over and rubbed briskly
over the contacts seems to work very well.
Continued...
Be certain that all boards are firmly seated in their
slots or sockets. It may be necessary to replace old cabling which may
degrade over time and under high temperatures. Power supplies can also
cause many problems, thus, if possible, have the output voltages checked.
Monitors can cause strange behaviors on your system as well. It is also
highly recommended that computers be placed on some type of Surge Suppression
power strip since after a power outage occurs, the return of power back
on is usually a fairly high surge and can permanently damage sensitive
electrical components of your system.
Ed. PS/2 systems do
not need to be placed on surge suppressors. The peripheral equipment (monitors,
printers, scanners, etc) does benefit from the surge suppressor, however.
UPS need to be TRUE SINE WAVE!
Modified sine wave is NOT acceptable. Modified sine wave UPSs will give
you random PS/2 power supply power down, then power up and the UPS will
never trip Since the incoming AC power is OK, the UPS won't trip, but the
modified sine wave out to the PS/2 power supply will trigger random power
cycling.
Parity Memory
Parity memory is standard IBM memory with 32 bits of data
space and 4 bits of parity information (one check bit/byte of data). The
4 bits of parity information are able to tell you an error has occurred
but do not have enough information to locate which bit is in error. In
the event of a parity error, the system generates a non-maskable interrupt
(NMI) which halts the system. Double bit errors are undetected with parity
memory.
Error Correcting Code Memory
Traditionally, systems which implement only parity memory
halt on single-bit errors, and fail to detect double-bit errors entirely.
Clearly, as memory is increased, better techniques are required.
One technique to deal with double-bit errors is Error
Correcting Code (or sometimes Error Checking and Correcting). ECC can detect
and correct single bit-errors, detect double-bit errors, and detect some
triple-bit errors.
ECC works like parity by generating extra check bits with
the data as it is stored in memory. However, while parity uses only 1 check
bit per byte of data, ECC uses 7 check bits for a 32-bit word and 8 bits
for a 64-bit word. These extra check bits along with a special hardware
algorithm allow for single-bit errors to be detected and corrected in real
time as the data is read from memory.
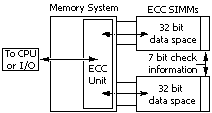 The data is scanned as it is written to memory. This scan generates a unique
7-bit pattern which represents the data stored. This pattern is then stored
in the 7-bit check space.
The data is scanned as it is written to memory. This scan generates a unique
7-bit pattern which represents the data stored. This pattern is then stored
in the 7-bit check space.
As the data is read from memory, the ECC circuit again performs
a scan and compares the resulting pattern to the pattern which was stored
in the check bits.
If a single-bit error has occurred (the most common form
of error), the scan will always detect it, automatically correct it and
record its occurrence. In this case, system operation will not be affected.
The scan will also detect all double-bit errors, though
they are much less common. With ouble-bit errors, the ECC unit will detect
the error and record its occurrence in NVRAM; it will then halt the system
to avoid data corruption. The data in NVRAM can then be used to isolate
the defective component.
In order to implement an ECC memory system, you need an
ECC memory controller and ECC SIMMs. ECC SIMMs differ from standard memory
SIMMs in that they have additional storage space to hold the check bits.
The Server 95 ECC support views memory in 1MB segments and has the ability
to deallocate a failing segment.
Results of Mixing Parity and ECC Memory
From Stephan Goll:
My box (95A) showed the showed the expected memory error.
I didn't know that I mixed ECC and parity (bankwise), so I ran the
memory tests. This procedure told me what I has been doing, disabled the
ECC-equipped banks, and the box after that ran fine with reduced memory.
I believe the reason is that the first bank rules the type of ram the box
wanted to see.
Btw, I realized that the memory in the first bank is tested
more intensive then in other banks, because I have failing mem-modules,
but they work very well in one of the other banks, even in the mem-tests
and under linux.
Error Correcting Code-Parity
(ECC-P) Memory
Previous IBM servers such as the 9585 were able to use
standard memory to implement what is known as ECC-P. ECC-P takes advantage
of the fact that a 64-bit word needs 8 bits of parity in order to detect
single-bit errors (one bit/byte of data). Since it is also possible to
use an ECC algorithm on 64 bits of data with 8 check bits, IBM designed
a memory controller which implements the ECC algorithm using the standard
memory SIMMs.
The following shows the implementation of ECC-P. When
ECC-P is enabled via the reference diskette, the controller reads/writes
two 32-bit words and 8 bits of check information to standard parity memory.
Since 8 check bits are available on a 64-bit word, the system is able to
correct single-bit errors and detect double-bit errors just like ECC memory.
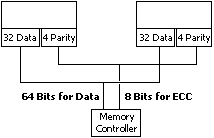 While ECC-P uses standard non-expensive memory, it needs
a specific memory controller that is able to read/write the two memory
blocks and check and generate the check bits. Also, the additional logic
necessary to implement the ECC circuitry make it slightly slower than true
ECC memory. With the Server 85 ECC-P implementation, the system views memory
as matched pairs of SIMMs and, in case of a double bit failure, will deallocate
both SIMMs in a matched pair. With the price between standard memory and
ECC has narrowed, IBM no longer implements ECC-P.
While ECC-P uses standard non-expensive memory, it needs
a specific memory controller that is able to read/write the two memory
blocks and check and generate the check bits. Also, the additional logic
necessary to implement the ECC circuitry make it slightly slower than true
ECC memory. With the Server 85 ECC-P implementation, the system views memory
as matched pairs of SIMMs and, in case of a double bit failure, will deallocate
both SIMMs in a matched pair. With the price between standard memory and
ECC has narrowed, IBM no longer implements ECC-P.
Note: Parity and ECC-on-SIMM memory can not be
installed within the same system. (Ed. untested)
Requirements to
use ECC-P
You have to use matched pairs of memory SIMMs in order
to use ECC-P.The 9585 is the only PS/2 that supports ECC-P. With matched
pairs, the 9585 supports ECC-P for the entire amount of supported system
memory (256MB max on K and N models, 64MB on X models). Unmatched
SIMMs can be installed in the Server 85-xXx ONLY,
however, ECC-P can be turned on for matched pair SIMMs only. For
Model 85-xXx ONLY
unmatched SIMMs will be run as normal parity memory if they are installed.
Enabling ECC-P
ECC capability can be turned on or off without changing
any hardware, memory, switches, or opening the cover; enabled or disabled
via menus on the System Partition (Ref Diskette). You may select
memory support from a memory checking method item on the system configuration
menu screens. This option allows the user to choose between ECC-P
or normal parity operation.
Performance
Degradation
ECC-P detection and correction takes place in the memory
controller rather than in the memory SIMM as on the Base 3 and 4 Processor
Complex of the Model 95. If ECC-P is enabled, it will cause up to a 14%
performance degradation compared to the more efficient Base 3 and 4 Processor
Complex (Model 95) which is only 3%. This performance degradation is only
for the memory subsystem, not for the total throughput. (Ed.
I have heard a few reports (retorts) that it's a little more noticeable
than that...)
As previously discussed, systems which employ ECC memory
have slightly longer memory access times depending on where the checking
is done. It should be stressed that this affects only the access
time of external system memory, not L1 or L2 caches. The following table
shows the performance impacts as a percentage of system memory access times
of the different ECC memory solutions.
Again, these numbers represent only the impact to accessing
external memory. They do not represent the impact to overall system performance
which is harder to measure but will be substantially less.
| Type |
SIMM |
Memory
Controller |
Impact to
Access Time |
| ECC |
X |
X |
3% |
| ECC-P |
|
X |
14% |
| EOS |
X |
|
None |
ECC on SIMMs (EOS) Memory
ECC On SIMM (EOS) is memory with the ECC logic function
completely contained
on the SIMM. This differs from true ECC, where the planar or complex
memory controller
provides the ECC logic. EOS provides detection and correction of any
single-bit error in each
byte of SIMM data before the data leaves the SIMM. EOS can upgrade
parity based
systems to a fully functional single-error-correct (SEC) ECC system.
EOS appears to a system like normal, 36 bit wide, 72 pin
FPM. 4MB EOS SIMMs
use IBM presence detect, and the 8MB (Tall and Wide), 16MB and 32MB
EOC SIMMs
have industry standard presence detects. All EOS uses gold tabs.
The only PS/2 systems that can use the 16 and 32MB EOS
are the 9585 K/N. With these systems, leave the memory checking in System
Programs as Parity. Do not enable ECC-P (software based ECC) because it's
redundant and slows the system down.
Mixing EOS and Parity?
> Can I use both EOS and parity SIMMs with parity together
in a PC-Server 320 ? Has anyone tested it?
Peter Wendt:
Not that I knew of. The EOS is ECC-On-SIMM...
basically a workaround to use some ECC sort of error detection on a systemboard
that is originally designed for Parity only (like the crappy Micronics
board in the 320 and 520) and the technical basis of it all is still Parity.
But the BIOS differs among the two. EOS is detected as
ECC and Parity... well... as Parity. This however triggers two different
routines for the error handling. The EOS memory is capable to catch single
bit failures on its own and only signals a corrected bit failure to the
systemboard logic (and then further to the POST code at next power on,
respectively to the failure report and to e.g. Netfinity Manager), while
Parity just dumps into a blue screen or NMI error routine of any kind.
I have a 520 - an 8641-MZV with 128MB of EOS memory. I
tried using the 8 32MB Parity modules I got for my Server 85 9585-0NG -
and they did not work (very well - wonder why). Trying to "mix and match"
2 sets of each caused a power on error 200-something right from the start.
Ed. Tom: Is that so? The EOS modules should
identify as parity SIMMs, otherwise the system would try using all 39 or 40
data pins instead of the 36 present on parity and EOS modules (some EOS modules
use a special error reporting method/lines, however this in not supported by
any of the PS/2 machines afaik).
|