|
Shared RAM
Busmaster/DMA
Streamers
LANStreamer
EtherStreamer
PeerMaster
Source: Local Area Network Concepts and Products: Adapters, Hubs and ATM (PDF HERE)
HTML-ized by Louis Ohland. Edited by Tomáš Slavotínek.
Shared RAM
Shared RAM adapters derive their name from the fact that
they carry on-board RAM and share that RAM with the system processor. The
memory on the adapter card is mapped into an unused block of system memory
above the 640 KB line in the upper memory area. The upper memory area is
the 384 KB of memory immediately above the 640 KB line. The UMB area is
reserved for I/O adapters.
The server processor can access this memory in the adapter
in the same manner in which it accesses system memory. The starting address
of the shared RAM area is determined by the adapter device driver unless
the adapter is an MCA Adapter, in which case the address is determined
by the setting of the reference diskette.
In size, shared RAM can be 8, 16, 32, or 64 KB depending
on which adapter is used and how it is configured. Adapter cards with 64
KB support RAM paging which allows the system to view the 64 KB of memory
on the card in four 16 KB pages. This scenario only requires 16 KB of contiguous
system memory instead of the 64 KB required when not using RAM paging. RAM
paging will not work unless the adapter's device driver supports it. All
IBM NetBIOS products support RAM paging.
The shared RAM area itself contains
various status and request blocks, service access points and link station
control blocks, receive buffers, and transmit buffers. It is possible to
alter the size and number of the transmit and receive buffers by altering
parameters associated with adapter device drivers. A shared RAM adapter
is the Short IBM Token-Ring 16/4 /A (16-bit).
Primary advantages of the shared RAM architecture:
- On-board logical link control (LLC)
- Low memory requirements for DOS environments
- Huge installed base of compatible applications and device drivers
Main disadvantage of the shared RAM architecture
The main disadvantage of shared RAM architecture is that
any data movement between the shared RAM area and system memory must be
done under direct control of the system's CPU. This movement of data to
and from the shared RAM must be done because applications cannot operate
on data while it resides in the shared RAM area. To compound matters,
MOVE instructions from/to the shared RAM are much slower than the same
MOVE instruction from/to the system memory because they occur across an
I/O expansion bus. This means that when shared RAM adapters are involved,
the CPU spends a significant amount of time doing the primitive task of
moving data from point A to point B.
On lightly loaded servers providing traditional productivity
apps such as word-processing, spreadsheets, and print sharing, this is
not really a problem. But for applications such as databases or for
more heavily loaded file servers, this can be a major source of performance
degradation.
Bus Master/DMA Adapters
The TR Network 16/4 Busmaster
was the first generation of bus master LAN adapters from IBM. It
employed the 64 KB on-board adapter memory as a frame buffer to assemble
frames before they were sent to the server or sent from the server to the
network. The time elasticity provided by this buffer allowed the
token-ring chip set to complete its processing and forwarding of the frame
before the frame was lost; known as overrun (receive) or underrun (transmit).
The 16-bit MCA bus master was capable of burst mode DMA.
It was limited to using only the first 16 MB of system address memory because
of it's 24-bit addressing capabilities . Bus master/DMA adapters utilize
on-board DMA controllers to transfer data directly between the adapter
and system memory without involving the system processor.
Bus master/DMA adapters do not use the shared RAM mechanism
to transfer data to system memory. However, bus master/DMA adapters do
use shared ROM when they are performing the remote initial program load
(RIPL) function.
Primary advantages of the bus master/DMA adapter:
- Able to transfer data directly to and from system memory without
involving system processor.
- High performance levels can be achieved in certain environments
(OS/2 with LAPS or NTS/2 and Novell ODI), which cannot be obtained using
the shared RAM architecture.
Primary disadvantages of the bus master/DMA adapters:
- High system memory consumption:
In a DOS environment, the NDIS drivers for the 16/4 Adapter II may consume
up to three times as much system memory as those used for the shared RAM
adapters. Memory consumption is not so critical in the OS/2 environment,
so it makes more sense to use these adapters in the OS/2 environment and
avoid the DOS environment unless you are not memory constrained. The bus
master/A adapter is not supported in a DOS environment.
- Poor performance in certain DOS environments:
In a DOS environment the 16/4 Adapter II and LANStreamer are supported
with NDIS and ODI drivers. Poor performance may occur in an NDIS environment
when using LAN Support Program's DXME0MOD.SYS which is an 802.2 NDIS protocol
driver. This driver must be used when running 802.2 applications such as
PC/3270, AS/400 PC Support, DOS APPN, and TCP/IP V2.X for DOS when using
the ASI (802.2) interface.
- No on-board logical link control (LLC):
Since the adapter itself does not implement an LLC stack, one must be written
into the NDIS MAC driver or protocol driver if one is needed. This means
that additional system memory will be needed to implement the LLC stack.
This is not much of a consideration in the OS/2 environment, but it may
affect a memory constrained environment like that of DOS. Novell NetWare
users will have to add a NetWare Loadable Module (NLM), LLC8022.NLM, for
example, to add LLC support to the configurations of their server machines.
The primary reason for doing so would be to enable the server adapter to
be monitored as a critical resource from LAN Network Manager.
- Can't address >16 MB when bus master card only has 24 address lines:
Bus master cards equipped with 24 address
lines (such as the 16/4 Adapter II and LANStreamer MC16) cannot access
memory over 16MB. Problems could occur in a machine with 24MB and a LAN
application that resides in memory somewhere above the 16MB line. If you
have more than 16MB of real memory in a machine, you should use an adapter
with 32 address lines such as the LANStreamer MC32. The
really ironic thing is that a shared RAM adapter with only 24 address lines
has no trouble getting to memory above the 16 MB line simply because the
shared RAM adapter relies on the system processor to move the data to and
from the card. The bus master cards perform this data transfer themselves
and must have the ability to address all of the memory within the machine.
It may be possible to write adapter device drivers which will overcome
this problem.
Streamers
See also Introduction to IBM LANStreamer Adapters.
LANStreamers
LANStreamer adapters are based on the LANStreamer chip
set, a token-ring implementation developed by IBM. This chip set provides
performance approaching the theoretical maximum capabilities of 16Mbps
token-ring, as well as several important new features.
32-Bit Bus Master Interface:
The LANStreamers provide a 32-bit bus master interface to the Micro Channel
supporting both 32-bit addressing and 32-bit data moves. LAN Streamer's
bus mastering capabilities free the system CPU from having to move data
between the LAN adapter and system memory, freeing the system CPU for other
work and resulting in significantly lower system CPU utilization than shared
RAM adapters.
As the amount of data kept on servers has increased,
the size of the file cache needed on the server has also increased. LANStreamers
with 32-bit addressing are able to directly address 4 GB of system memory
and are better suited to support these servers as well as other applications
which have hefty system memory requirements.
LANStreamer adapters are capable of moving data across
the Micro Channel over four times as fast as competitive 16-bit bus master
adapters. This high transfer rate is achieved through two improvements:
doubling the amount of data moved with each data transfer from 16 bits
to 32 bits, and the streaming data mode available on many new PS/2s (including
the PS/2 M95-0Mx) halves the time for each data transfer from 200 ns to
100 ns.
The throughput for the LANStreamer MC32 is quite high
relative to its predecessors, especially for small frames. This is
extremely important in client/server environments where research has shown
that the vast majority of frames on the network are less than 128 bytes.
The combination of these factors allows LANStreamer MC32
to achieve peak burst transfer rates across the Micro Channel of 40 Mbps.
LANStreamer's high Micro Channel transfer rates allow it to minimize its
utilization of the Micro Channel, leaving bus capacity for other adapters
and applications.
The LANStreamer Micro Channel interface also supports
parity checking for both data and address. This feature provides added
robustness for mission critical applications.
A consequence of the high LANStreamer throughput is higher
CPU utilization. This can happen because the LANStreamer can pass
significantly more data to the server than earlier adapters. This
means more frames per second must be processed by the server network operating
system. Higher throughput is the desired effect but what this also means
is that the bottleneck sometimes moves quickly to the CPU when servers
are upgraded to incorporate LANStreamer technology.
Of course, other components can emerge as the bottleneck
as throughput increases. The wire (network bandwidth) itself can
become a bottleneck if throughput requirements overwhelm the ability of
the network technology being used. For example, if an application
requires 3 MBps of throughput, then a token-ring at 16 Mbps will not perform
the task. In this case a different network technology must be employed.
Pipelined Frame Processing: LANStreamer
achieves superior performance by changing how token-ring adapters
transmit and receive frames.
Traditional token-ring adapters all use variations of
a store-and-forward architecture, where frames are moved into buffers in
the adapter memory and processed by the adapter before being moved to their
final destination. The processing that must be done includes managing the
adapter's interface with the device driver, handling hardware and software
interrupts, managing adapter buffers, checking frame status, managing the
protocol handler, and moving frames in or out of buffer memory. MAC (Media
Access Control) frame processing is also performed by the adapter processor.
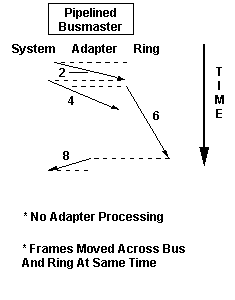
In contrast, LANStreamer uses a pipelined architecture.
Frames are streamed directly between the token-ring and attaching system
memory without being stored on the adapter and without any adapter processor
intervention. Rather than first moving frames from system memory to the
adapter, and then moving them from the adapter to the ring, LANStreamer
simultaneously moves the frame from the system onto the adapter and out
onto the ring. This new architecture is made possible by the implementation
in VLSI of the functions previously done in software by the adapter processor.
This dramatically improves performance, because the processing time required
for each frame is the major bottleneck in the store-and-forward architecture.
To transmit a frame, the attaching system adds a control
block to its transmit queue. The adapter bus master interface reads this
control block into special hardware registers, and begins moving the frame
from the system to the token-ring. There is a small FIFO (first-in-first-out)
buffer on the adapter to guarantee that there is always data available
to move onto the ring (in case the adapter loses the Micro Channel temporarily).
Data is moved into this FIFO from system memory, and simultaneously moved
from the FIFO onto the token-ring. The process for receiving frames is
similar. The adapter hardware sorts out MAC frames and they are processed
on the adapter by the adapter processor. This processing does not affect
the throughput performance of user information frames, which are passed
directly to the system with no processor intervention.
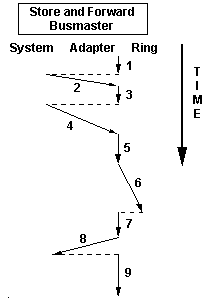
Store and Forward vs Pipeline Architecture
|
|
|
Store and Forward
1. Adapter processor sets up a read control block
2. Adapter bus master interface reads control block
3. Adapter processor sets up to read frame
4. Adapter bus master interface reads frame
5. Adapter processor sets up to put frame on ring
6. Adapter Xmits frame on ring
7. Adapter sets up to inform system of Xmit completion
8. Inform system of Xmit completion
9. Post processing (free buffers, etc.)
|
Pipelined
2. Adapter bus master interface reads control block
4. Adapter bus master interface reads frame
6. Adapter Xmits frame on ring
8. Inform system of Xmit completion
|
The result of the pipelined approach is that the adapter
is never the bottleneck for throughput. If the system can handle it, LANStreamer
can transfer or receive frames at 16 Mbps, even at small frame sizes. This
means LANStreamer is capable of up to 48,000 frames
per second throughput. By comparison, the bus
master adapter has a throughput capacity approaching 3,000 frames per second.
In a server such as the PS/2 Model 95-0MF, with a fast 50 MHz 80486 processor,
a high bandwidth Micro Channel bus, and a LANStreamer token-ring adapter,
each critical server component is optimized to provide high LAN I/O throughput
capacity.
Another result of the pipelined architecture is the minimization
of adapter latency. Adapter transmit latency is defined as the interval
from when the adapter is informed of a frame to transmit to when the first
bit of the frame is placed on the ring. Adapter receive latency is defined
as the interval from when the last bit of the frame is copied from the
ring into the adapter to when the last bit of the frame is in system memory
and the system is informed of the frame.
Since there is no time spent on processing, and the frame
is moved out of the adapter at the same time as it is moved in, LANStreamer
adapter latency approaches the theoretical minimum possible. In a traditional
adapter, the latency due to adapter processing is compounded by the storing
of the frame in adapter memory. This makes the adapter latency increase
as frame size increases (since it takes longer to move the whole frame
in and out of adapter memory). In contrast, LANStreamer latency is essentially
constant (less than 30 microseconds), regardless of frame size. By comparison,
the latency to just store and forward a 4096-byte frame onto a 16 Mbps
ring, without considering any processor overhead, is 2048 microseconds.
Multiple Group Addressing: Group addressing
is part of the token-ring architecture, but today's token-ring adapters
only implement one group address, which is not very useful for most applications.
By implementing multiple group addressing, LANStreamer offers complete
hardware support for multicasting. Multicasting can be thought of as a
limited broadcast. Rather than sending a frame to either a single destination
station or broadcasting it to every station on the network, multicasting
allows a user to send frames to a limited group of destinations. Stations
may assign themselves to a particular group by setting one of the 256 hardware
group addresses available on LANStreamer. These 256 addresses allow each
LANStreamer station to belong to up to 256 groups, but there can be more
than 256 groups on a network.
Examples of applications which would use multiple group
addressing include protocols and applications where large amounts of data
are distributed to users. For example, TCP/IP uses ARP (Address Resolution
Protocol) frames for discovering routes. Rather than burdening every station
with receiving and discarding these frames, group addresses could be utilized/
so that only stations using the TCP/IP protocol used these frames. Another
example might be a stock market application. Brokers might want to belong
to groups which received information on specific stocks of interest, rather
than receiving everything and having to sort through it. A third example
is software distribution. Users owning a specific application would have
an associated group address. Updates to that application could be automatically
sent to the group.
Today's implementation can be described as follows: frames
are sent to every station on the network using broadcast. Each station's
CPU sorts each frame using the functional address, and discards frames
not intended for it. There are obvious disadvantages to this approach.
Each station's CPU must sort every broadcast frame (whether it is intended
for the local station or not) tying it up for significant amounts of time.
In one case, where TCP/IP was being used on the network, users reported
that even stations that did not use TCP/IP were spending 40%-50% of their
CPU cycles decoding ARP frames.
Multiple group addressing has significant advantages over
today's implementation. Frames are sorted in hardware by the adapter, so
the station only sees frames that are meant for it. Functional addresses
are token-ring only, while group addressing is designed in all major LAN
topologies and is the multimedia standard. It is important to note that
token-ring adapters without group addressing can coexist on the ring with
LANStreamer adapters using the multiple group addressing feature; the current
adapters won't be able to take advantage of this feature.
Priority Mechanisms: The LANStreamer chip
set provides two mechanisms for prioritizing frames passing through the
token-ring adapter. These are priority queueing in the adapter, and priority
tokens on the ring. LANStreamer implements two prioritized transmit queues.
High priority frames can be placed on the higher priority queue to be processed
ahead of lower priority frames. The LANStreamer adapter will reserve priority
tokens on the ring for these high priority frames.
The ability to prioritize traffic is valuable for applications
which have high bandwidth requirements or need to minimize response time.
In today's token-ring adapters, frames are handled on a first-come first-served
basis. A high priority frame must wait in line behind lower priority frames
before being transmitted. Applications such as multimedia will benefit
from LANStreamer's priority mechanisms by being able to both guarantee
bandwidth on the ring through priority token reservation, and minimize
delays by using the priority queue.
Both these priority mechanisms transparently coexist with
current token-ring implementations. The priority token is part of the token-ring
architecture, and is already used in certain applications such as bridging.
With LANStreamer, IBM has provided a mechanism, in conjunction with the
priority queue, for making priority token reservation available to user
applications. The priority queue is a system interface implementation that
does not affect token-ring operation.
On-Card STP and UTP Support: The
LANStreamer adapters include on-card filters for both STP and UTP media.
LANStreamer MC 32 includes RIPL support for both LAN Server (all levels)
and NetWare (V3.X and beyond). LANStreamer provides full network management
support, and is fully compatible with LAN Network Manager. The LANStreamer
MC 32 adapter is available for the 3172 Interconnect
Controller.
Another advantage of this technology is that since adapter memory buffers
are no longer required, the adapter is less expensive to produce.
The LANStreamer technology is used in the IBM Auto LANStreamer Adapters
for PCI and MCA as well as the EtherStreamer and Dual EtherStreamer MC
32 LAN adapters.
EtherStreamer
The EtherStreamer LAN adapter supports duplex
mode, which allows the adapter to transmit as well as receive at the same
time. This provides an effective throughput of 20 Mbps (10 Mbps on
the receive channel and 10 Mbps on the transmit channel). To implement
this feature, an external switching unit is required.
PeerMaster
The PeerMaster technology takes LAN adapters one step
forward by incorporating an on-board Intel i960 processor. This processing
power is used to implement per port switching on the adapter without the
need for an external switch. With this capability, frames can be
switched between ports on the adapter, bypassing the file server CPU totally.
If more than one card is installed, packets can be switched both within
cards and between cards. The adapters utilize the Micro Channel to
switch inter-card and can transfer data at the very high speed of 640 Mbps.
The IBM Quad PeerMaster Adapter is a four-port
Ethernet adapter that utilizes this technology. It is a 32-bit Micro
Channel bus master adapter capable of utilizing the 80 MBps data streaming
mode across the bus either to/from system memory or peer-to-peer with another
PeerMaster adapter.
The Quad PeerMaster is a type 5 Micro Channel adapter.
This refers to the physical size of the adapter. A type 5 adapter
is 13.1 x 4.825 inches and is larger than normal MCA adapters (11.5 x 3.475
inches). It fits in specific servers and only in certain slots.
Servers that support the type 5 adapters include the Server 320, 500 and
520. Refer to Server Products for more information on these
servers.
It ships with 1 MB of memory. Each port on an adapter serves a
separate Ethernet segment. Up to six of these adapters can reside on a
single server and up to 24 segments can be defined in a single server.
This adapter can also be used to create virtual networks (VNETs). a
single network, eliminating the need to implement the traditional router
function either internal or external to the file server.
The Ethernet Quad PeerMaster Adapter is particularly appropriate when
there is a need for:
- Switching/Bridging traffic among multiple Ethernet segments
- Attaching more than eight Ethernet 10Base-T segments to the server
- Attaching more than four Ethernet 10Base-2 segments to the server
- Providing switching between 10Base-T and 10Base-2 segments
- Conserving server slots
An add-on to NetFinity provides an advanced Ethernet subsystem
management tool. Parameters such as packets/second or total throughput
can be monitored for each port, for traffic within an adapter, or for traffic
between adapters.
By using NetFinity, you can graphically view the data, monitor
for predefined thresholds, and optionally generate SNMP alerts.
|